
Im Zeitalter des Industrial IoT und der konstant steigenden anfallenden Menge an Daten ist die Forderung nach effizienten Wiederherstellungsmethoden im Falle eines Festplattenausfalls notwendiger denn je geworden, um den Verlust kritischer Daten zu verhindern. Eine der am weitesten verbreiteten Techniken zum Schutz vor Datenverlust ist das Redundant Array of Independent Disks, besser bekannt unter dem Kürzel RAID. Im Laufe der Zeit haben sich verschiedene Methoden zur Implementierung von RAID entwickelt, die gängigerweise als RAID-Level bezeichnet werden.
Was ist RAID?
Ein RAID ist ein System, welches dazu dient, Daten auf mehreren unabhängigen Festplatten zu speichern, um deren Redundanz zu erhöhen und dem Benutzer eine einfache Wiederherstellungsmethode im Falle eines Datenverlustes zur Verfügung zu stellen. Darüber hinaus kann ein RAID-System auch eingesetzt werden, um den Datendurchsatz eines Systems zu erhöhen und so höhere Schreibgeschwindigkeiten zu erzielen. Einem RAID-System liegen dabei in der Regel zwei Methoden zugrunde, das Disk Striping und das Disk Mirroring.
Was ist Disk Striping?
Disk Striping bezeichnet die Unterteilung eines Datenblocks in Streifen und die Speicherung der partitionierten Datenstreifen auf mehreren Blöcken einer Festplatte. Striping hilft bei mehreren Benutzern, die gleichzeitig auf die gespeicherten Daten zugreifen, ihre I/O-Operationen zu überlappen, um die Effizienz und Geschwindigkeit aller Vorgänge, die sie auf dem System durchführen, zu erhöhen. Der größte Nachteil von Disk Striping liegt in der fehlenden Redundanz der Daten, wodurch die Fehlertoleranz des Systems gering ist.
Was ist Disk Mirroring?
Disk Mirroring (Festplattenspiegelung) bezeichnet dagegen das Kopieren der gesamten Daten und ihrer Metadaten, die auf einer Festplatte gespeichert sind, auf eine andere Festplatte. Dies hilft bei mehreren Überschneidungen über dieselben Daten, da auf jedes Laufwerk für den Vorgang zugegriffen werden kann. Durch die dabei entstehende Redundanz der Daten hat der Nutzer die Möglichkeit, verlorene Daten im Falle eines Festplattenausfalls wiederherzustellen. Der größte Nachteil beim Disk Mirroring ist der hohe Hardware-Einsatz und die fehlende Absicherung gegen den Ausfall mehrerer Festplatten.

Was sind RAID-Level?
Disk Striping und Disk Mirroring Techniken werden in verschiedenen Kombinationen verwendet, um verschiedene Implementierungen von RAID zu bilden. Diese werden allgemein als RAID-Level bezeichnet. Die gängigsten RAID-Level sind RAID 0 bis RAID 6. Einige dieser Varianten sind miteinander verschachtelt, um weitere Variationen der RAID-Level zu bilden. eine der häufigsten ist RAID 10 und RAID 01. Jedes RAID-Level variiert dabei in Bezug auf Betriebsgeschwindigkeit, Redundanz und Fehlertoleranz.
Übersicht der verschiedenen RAID-Typen
RAID 0
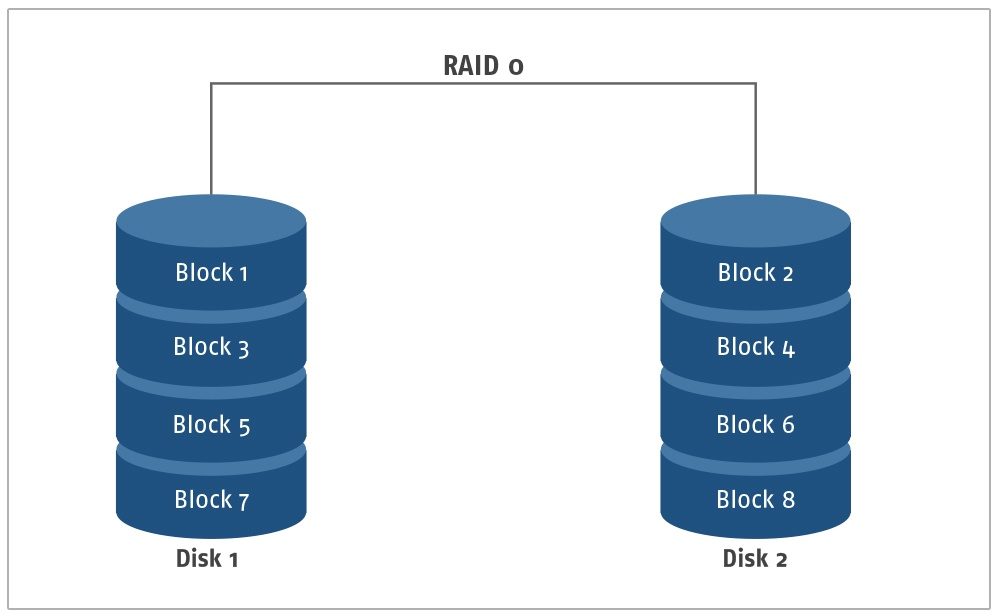
Übersicht: Die RAID 0 Konfiguration basiert nur auf der Disk Striping-Methode. Die Daten werden in Streifen unterteilt und in gleich großen Blöcken, die allgemein als Sektoren bezeichnet werden, auf die Laufwerke geschrieben. Die ausschließliche Verwendung von Disk Striping in dieser Konfiguration ermöglicht es mehreren Benutzern, alle I/O-Operationen zu überlappen, da ein einzelner Benutzer nicht auf den gesamten Datenblock für die Operation zugreifen muss und nur auf den Block zugreifen kann, der aus dem gewünschten Teil der Daten oder Metadaten besteht. Die Lese-/Schreibgeschwindigkeiten sind in der Regel unter RAID 0 schneller als bei allen anderen Konfigurationen. Die Daten können auf die Sektoren von mehr als einem Laufwerk verteilt werden. Diese Konfiguration wurde mit Blick auf verbesserte Lese-und Schreibgeschwindigkeiten entwickelt, um einen effizienten und schnellen Zugriff auf Daten zu ermöglichen.
Nachteile von RAID 0: Da es für diese Konfiguration keine Paritätsblöcke gibt, ist keine Redundanz erforderlich. Dies führt dazu, dass diese Konfiguration fast keine Fehlertoleranz aufweist. Der Ausfall eines einzelnen Laufwerks führt somit zu einem vollständigen Datenverlust, da die Daten in Fragmenten „gestreift“ und über verschiedene Laufwerke geschrieben wurden. Der Zugriff auf die Daten ist nur möglich, wenn alle Laufwerke optimal funktionieren. Aufgrund des Fehlens eines Paritätsblocks gibt es auch keine Möglichkeit, die Daten wiederherzustellen, sobald ein Festplattenfehler auftritt.
Anwendungsfall: Die RAID 0-Konfiguration ist ideal für ein Einzelplatzsystem, das zur Speicherung temporärer oder unkritischer Daten verwendet wird. RAID 0 kann auch für mehrere Benutzer verwendet werden, da es die Überlappung von I/O-Operationen ermöglicht. Diese Konfiguration wird für Aktivitäten wie die Bearbeitung von Bildern oder Videos oder die Ausführung von Anwendungen empfohlen, die eine hohe Ressourcenbandbreite erfordern.
RAID 1
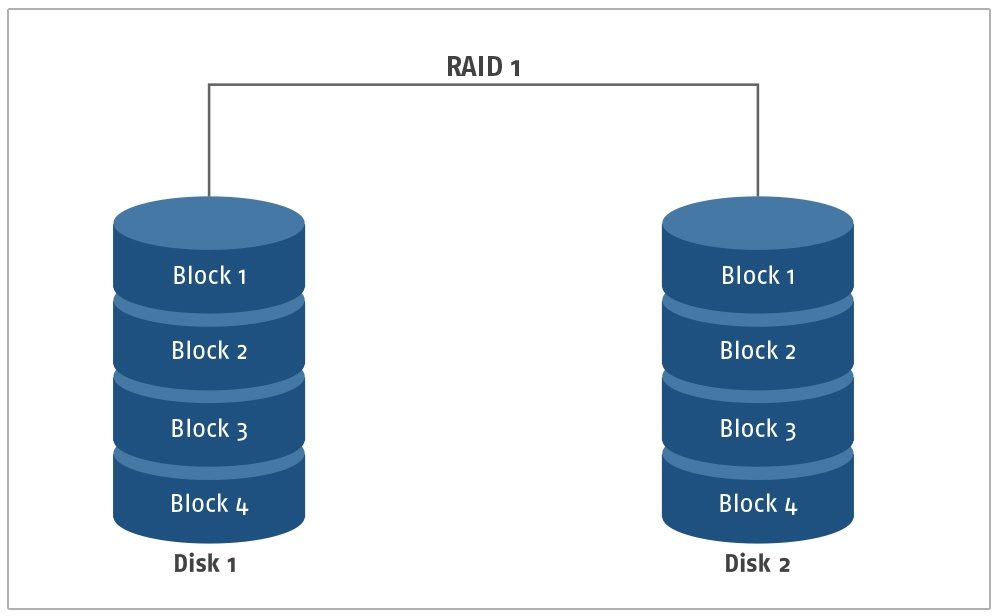
Überblick: Da in der vorherigen RAID 0-Konfiguration keine Redundanz vorhanden ist, gilt RAID 1 als die erste echte RAID-Konfiguration, da es Techniken zur Gewährleistung der Redundanz innerhalb des Systems verwendet. RAID 1 verwendet Disk Mirroring ohne Disk Striping, um eine identische Kopie der auf einer Festplatte gespeicherten Daten zu erstellen. Die Leseoperationen für diese Konfiguration sind vergleichsweise schnell, da mehrere Benutzer ihre Leseoperationen überlappen können, indem sie auf eine der verfügbaren Festplatten zugreifen, die die gleichen Daten enthalten. Die Schreiboperationen sind dagegen deutlich langsamer, da es eine erhöhte Anzahl von n Schreiboperationen gibt (wobei n die Anzahl der verwendeten Platten ist), die zu einer einzigen Schreibfunktion hinzugefügt werden. Aufgrund der hinzugefügten identischen Festplatte kann ein einzelner Festplattenfehler über das zweite Laufwerk, das identische Daten enthält, behoben werden.
Nachteile von RAID 1: Angesichts der Notwendigkeit, die Zuverlässigkeit innerhalb der gespeicherten Daten aufrechtzuerhalten, muss eine Änderung in einer Festplatte auch auf allen anderen Festplatten vorgenommen werden.
Anwendungsfall: Die RAID 1-Konfiguration ist perfekt für jedes Mehrbenutzersystem, das kritische Daten mit maximaler Verfügbarkeit speichern muss. Bei identischen Laufwerken können auch andere Benutzer auf die Daten zugreifen, während ein anderer Benutzer dieselben Operationen durchführt. Dadurch eignet es sich für jede Situation, in der schnelles Lesen und Arbeiten mit anwendungskritischen Daten erforderlich ist.
RAID 4
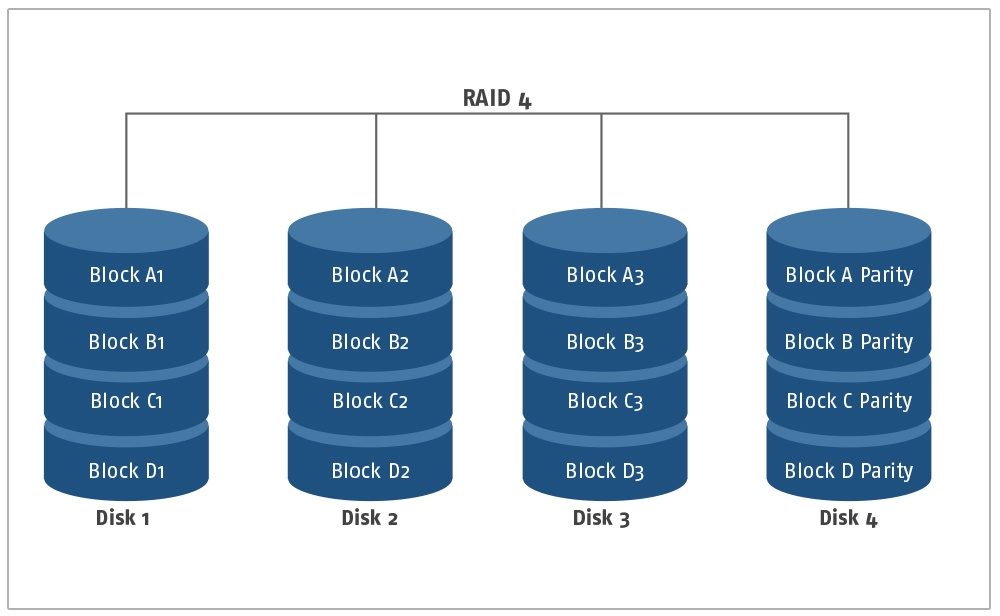
Übersicht: Die RAID 4 Konfiguration verwendet Disk Striping und Paritätsdaten, um Redundanz und überlappende Lesefunktionen für mehrere Benutzer zu gewährleisten. Für eine RAID 4 werden mindestens drei Festplatten benötigt, von denen zwei für Disk Striping und die dritte als Paritätsblock verwendet werden, um die Verfügbarkeit der Daten zu gewährleisten. Die blockweise Parität im RAID 4-Verbund sorgt dafür, dass mehr Metadaten in einem einzigen Segment der Festplatte gespeichert werden. Diese Konfiguration ist im Grunde genommen eine RAID 0-Konfiguration in Verbindung mit Paritätsblöcken, um dem Benutzer eine begrenzte Redundanz zu bieten. Die hinzugefügte Paritäts-Disk ermöglicht es dem Benutzer, die Daten unter Verwendung der Informationen aus der Parity-Disk im Falle eines Festplattenausfalls oder eines Datenverlustes neu aufzubauen. Angesichts des zusätzlichen Paritätslaufwerks sind Schreibvorgänge in dieser Konfiguration deutlich langsamer, da der große Paritätsblock jedes Mal aktualisiert werden muss, um die Korrektheit der Daten zu erhalten. Solange das Paritätslaufwerk intakt ist, kann ein System mit RAID-4-Konfiguration auch nach mehreren Festplattenausfällen wiederhergestellt werden.
Nachteile von RAID 4: Im Falle eines Festplattenausfalls ist der Rekonstruktionsprozess zwar zuverlässig, aber wesentlich langsamer als in der RAID-1-Konfiguration. Die Daten müssen mit den Metadaten aufgebaut werden, die in den Paritätsinformationen gespeichert sind und erlauben keine identische Kopie von Daten, wie bei einem RAID 1-Verbund. Hinzu kommt, dass der Schreibvorgang aufgrund der Notwendigkeit, den Paritätsblock zu aktualisieren, deutlich langsamer ist.
Anwendungsfall: Die RAID 4-Konfiguration eignet sich für jedes System, das für die Speicherung kritischer Daten ausgelegt ist und hauptsächlich zum Lesen von Daten verwendet wird. Aufgrund der fest belegten Paritätsplatte bei RAID 4 ist in der Praxis die RAID 5- oder RAID 6-Konfiguration deutlich weiter verbreitet.
RAID 5
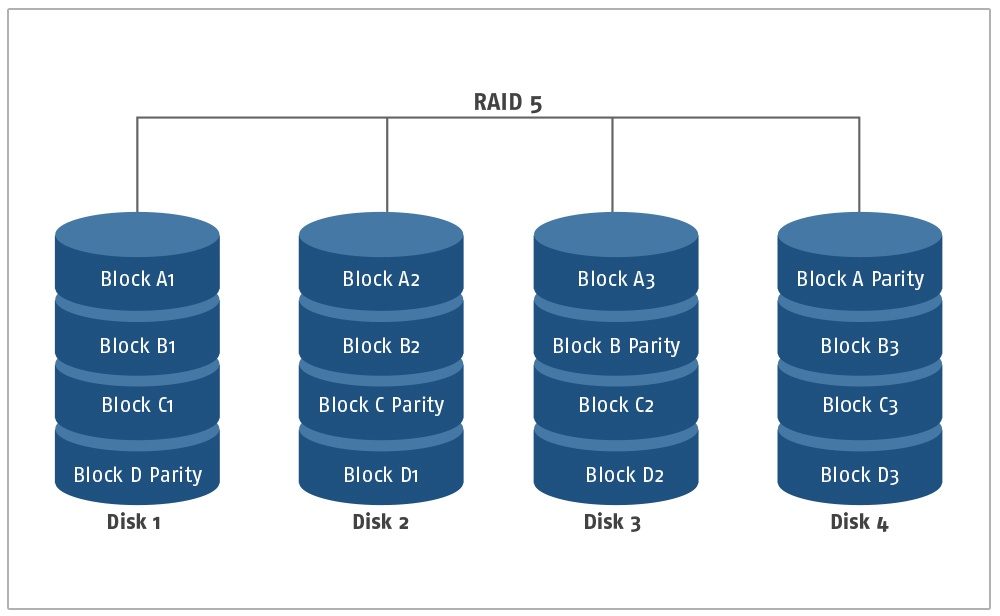
Übersicht: Die RAID 5-Konfiguration kann als eine verbesserte Iteration der RAID 4-Konfiguration definiert werden. In dieser Konfiguration werden nicht alle Paritätsinformationen auf einem Laufwerk gespeichert, sondern gleichmäßig auf den Laufwerken verteilt. Unter Verwendung der Parität eines jeweiligen Blocks werden nur zwei Blöcke mit zugehörigen Informationen benötigt, um die Daten im dritten Block herauszufinden. So entsteht eine deutlich verbesserte Lese- und Schreibgeschwindigkeit im Vergleich zur RAID-4-Konfiguration. Da nur ein anderes Layout und keine zusätzliche Hardware erforderlich ist, ist die RAID 5-Konfiguration genauso kostengünstig und zuverlässig wie eine RAID 4-Konfiguration, dabei aber deutlicher performanter. Wie die RAID 4-Konfiguration kann auch RAID 5 Daten in den Laufwerken selbst bei mehreren Festplattenausfällen wiederherstellen. Deshalb ist die RAID 5-Konfiguration heute deutlich gängiger als RAID 4.
Nachteile von RAID 5: Durch die zusätzliche Verteilung der Paritätsblöcke sind die Datenübertragungsraten in der RAID 5-Konfiguration mit denen eines einzelnen Laufwerks vergleichbar. Die RAID 5-Konfiguration ist zwar tolerant gegenüber Ausfällen mehrerer Laufwerke, aber anfällig für einen kritischen Datenverlust, ohne die Möglichkeit, sie wiederherzustellen, wenn es einen weiteren Fehler gibt, während das System sich von einem früheren erholt.
Anwendungsfall: Diese RAID 5-Konfiguration wird für ein System empfohlen, das gleichermaßen stark für Lese-/Schreibfunktionen ist und so konzipiert ist, dass es kritische Informationen über eine bestimmte Aufgabe speichert. Diese Konfiguration gilt aufgrund ihres umfassenden Charakters bei der Durchführung von Operationen als das vielseitigste Layout für die RAID-Implementierung.
RAID 6
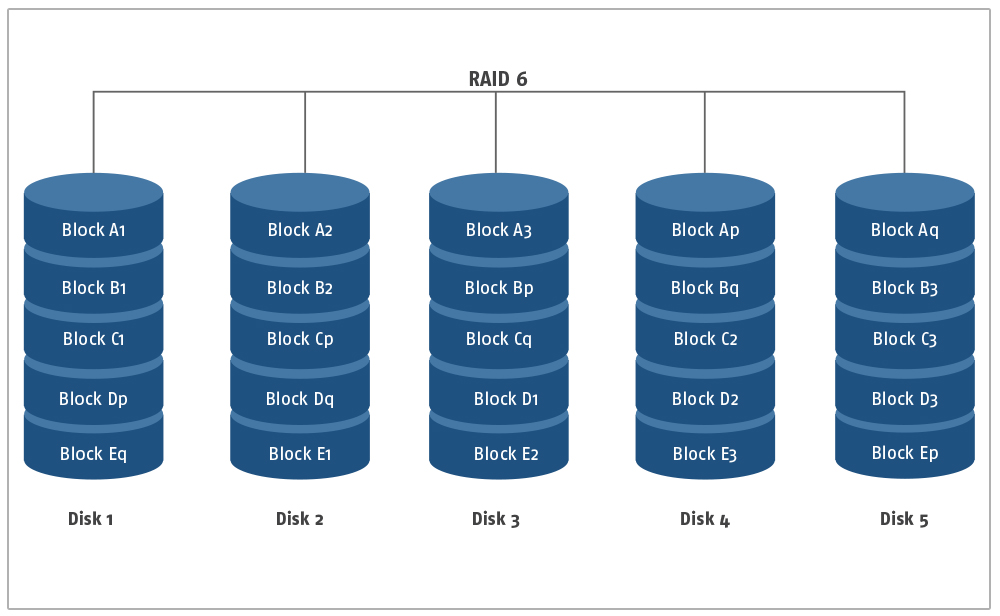
Übersicht: Um die RAID 5-Konfiguration weiter auszubauen und zu verbessern, wurde das RAID 6-Layout erstellt. Das Hauptmotiv dieses Layouts war es, die Schwachstellen der RAID-5-Implementierung zu beheben, während sie sich nach einem Festplattenfehler erholt. RAID 6 verwendet eine ähnliche Disk Striping-Technik mit Parität, die gleichmäßig über die Festplatten verteilt ist. Anders als bei RAID 5 kommt hier jedoch ein zusätzliches Festplattenlaufwerk zum Einsatz, das zum Speichern eines identischen Paritätsblocks verwendet wird, um eine erhöhte Sicherheit und Fehlertoleranz zu gewährleisten. Aufgrund der Einbeziehung eines zusätzlichen Festplattenlaufwerks erfordert das RAID 6-Layout eine Mindestanzahl von 4 Festplatten, die innerhalb eines Systems implementiert werden müssen. Das zusätzliche Laufwerk dient dazu, eine identische Kopie der Paritätsblöcke zu speichern, die ebenfalls gleichmäßig auf die Laufwerke verteilt sind. In diesem Layout speichert ein Laufwerk insgesamt zwei Paritätsblöcke.
Nachteile von RAID 6: Durch die Integration eines zusätzlichen Festplattenlaufwerks ist diese Implementierung teurer als ihr RAID 5-Pendant. Aus diesem Grund sind auch die Lese-/Schreibvorgänge vergleichsweise langsamer als bei RAID 5. Hinzu kommt, dass die Implementierung wesentlich komplexer ist – im Falle eines Festplattenausfalls dauert die Wiederherstellung von Daten ebenfalls länger.
Anwendungsfall: Die RAID 6-Implementierung wird für ein System empfohlen, das eine höhere Sicherheit erfordert, als unter RAID 5.
RAID 10
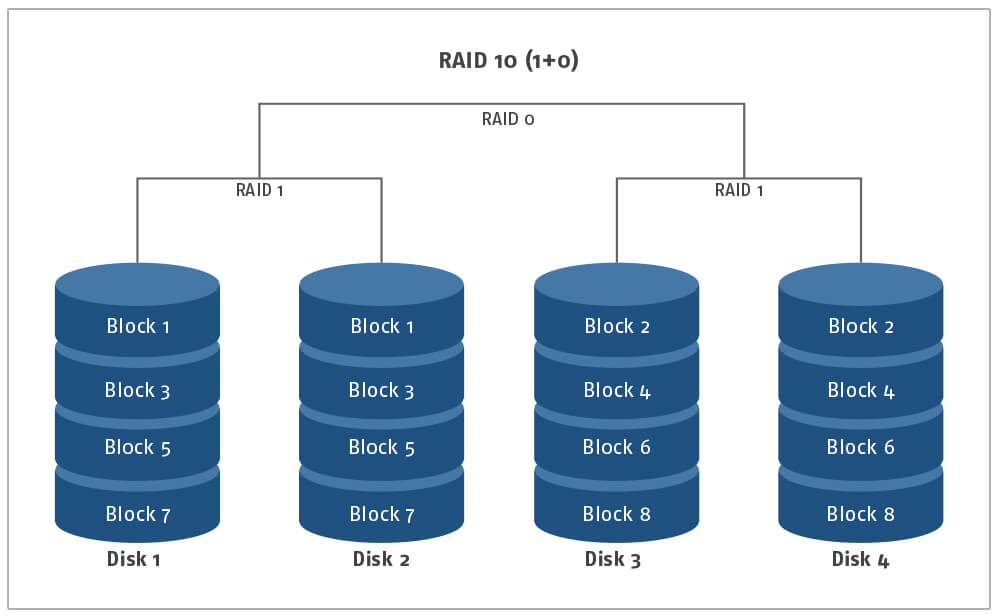
Übersicht: RAID 10 bezeichnet die Kombination aus RAID 0 und RAID 1. Diese Konfiguration verwendet sowohl Disk Striping als auch Disk Mirroring, und wurde entwickelt, um die hohen I/O-Raten der RAID 0-Konfiguration zusammen mit der Redundanz und Sicherheit durch RAID 1 zu kombinieren. Die Reihenfolge der Implementierung der Sublayouts ist äußerst wichtig, um sie richtig umzusetzen: RAID 10 wird allgemein als RAID 1+0-Implementierung bezeichnet, was bedeutet, dass zuerst RAID 1 und dann das RAID 0-Layout implementiert wird. Wenn Sie dem angegebenen Layout nicht folgen, kann eine RAID 01-Konfiguration entstehen, die ähnlich, aber nicht gleich ist. Im RAID 10-Verbund werden Festplatten zunächst gespiegelt, wie im RAID 1-Layout, und dann gestreift, ähnlich wie bei der RAID 0-Implementierung. Dadurch wird sichergestellt, dass im Falle eines Ausfalls die Daten leicht wiederhergestellt werden können, solange eines der gespiegelten Paare jeder gestreiften Festplatte optimal funktioniert.
Nachteile von RAID 10: Diese Lösung für die RAID-Implementierung ist angesichts der zusätzlichen Laufwerke und des hohen Speicherbedarfs für die Spiegelung der Daten äußerst teuer. Darüber hinaus müssen sich sowohl die gestreiften als auch die gespiegelten Vorgänge in synchronen Geschwindigkeiten bewegen, die relativ schwer zu erreichen sind, um eine dauerhafte und zufriedenstellende Leistung zu erzielen. Das Hinzufügen eines Laufwerks in einen bereits bestehenden RAID 10-Verbund kann darüber hinaus komplex sein, da die Daten gestreift und erneut gespiegelt werden müssen, um die Zuverlässigkeit zu erhalten.
Anwendungsfall: Die RAID 10-Konfiguration ist ideal für ein System, das eine hohe Geschwindigkeit von Lese-/Schreibvorgängen bei gleichzeitig breiter Verfügbarkeit von Daten und Redundanz im Falle eines Festplattenausfalls erfordert. Die Anwendungen, die heute häufig diese Art der Implementierung verwenden, sind E-Mail-Server, Webserver, Datenbankserver und andere Anwendungen, die eine hohe Festplattenleistung erfordern.
Auch InoNet bietet bei ihren IPCs unterschiedliche RAID-Level an. Sprechen Sie uns einfach an!


Ähnliche Beiträge

TOPS vs. TFLOPS vs. CUDA Cores: Leistungskennzahlen einfach erklärt
Begriffe wie TOPS, TFLOPS und CUDA Cores begegnen uns immer dort, wo KI-Modelle, Bildverarbeitung oder GPU-beschleunigte Anwendungen im Einsatz sind. Obwohl sie häufig verwendet werden, lassen sie...

Warum wird die Samsung 990 PRO NVMe SSD nicht mehr angezeigt?
Problembeschreibung Bei der Serie der Samsung 990 Pro NVMe SSDs kommt es bis zur Firmware-Version 4B2QJXD7 zu einer intermittierenden Nicht-Erkennung/BSOD. „Intermittierend” bedeutet in diesem...

Redundante Netzteile in Industrie PCs
Industrie PCs müssen selbst unter anspruchsvollen Bedingungen zuverlässig arbeiten: in Produktionslinien, Energieanlagen, Fahrzeugen oder an abgelegenen Außenstandorten. Ein zentraler Faktor für...

Ruggedization bei Industrie PCs
Industrie PCs müssen dort zuverlässig arbeiten, wo herkömmliche IT-Systeme längst an ihre Grenzen stoßen. In Produktionshallen, Fahrzeugen, Windparks oder an Außenstandorten herrschen Bedingungen,...